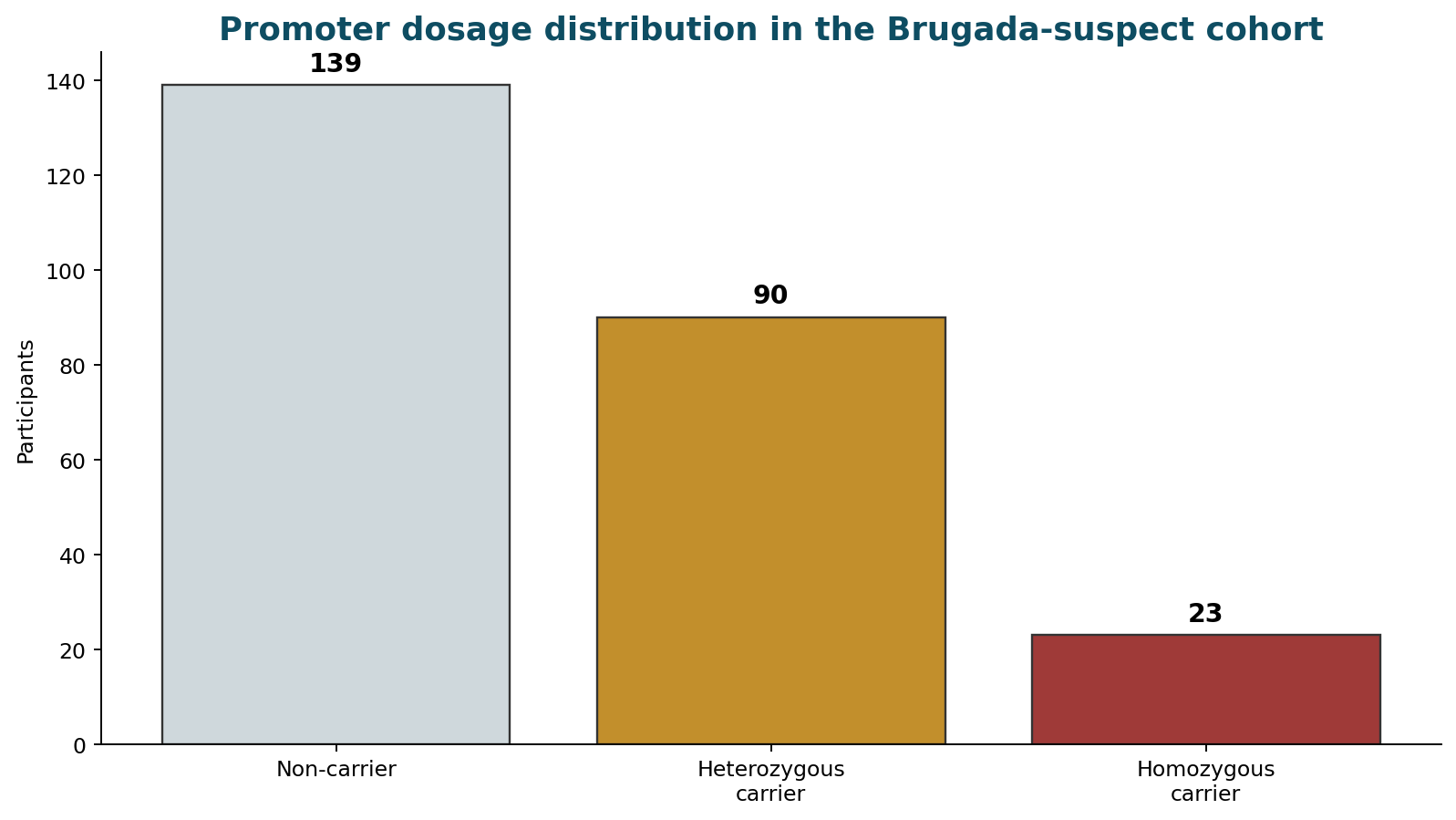
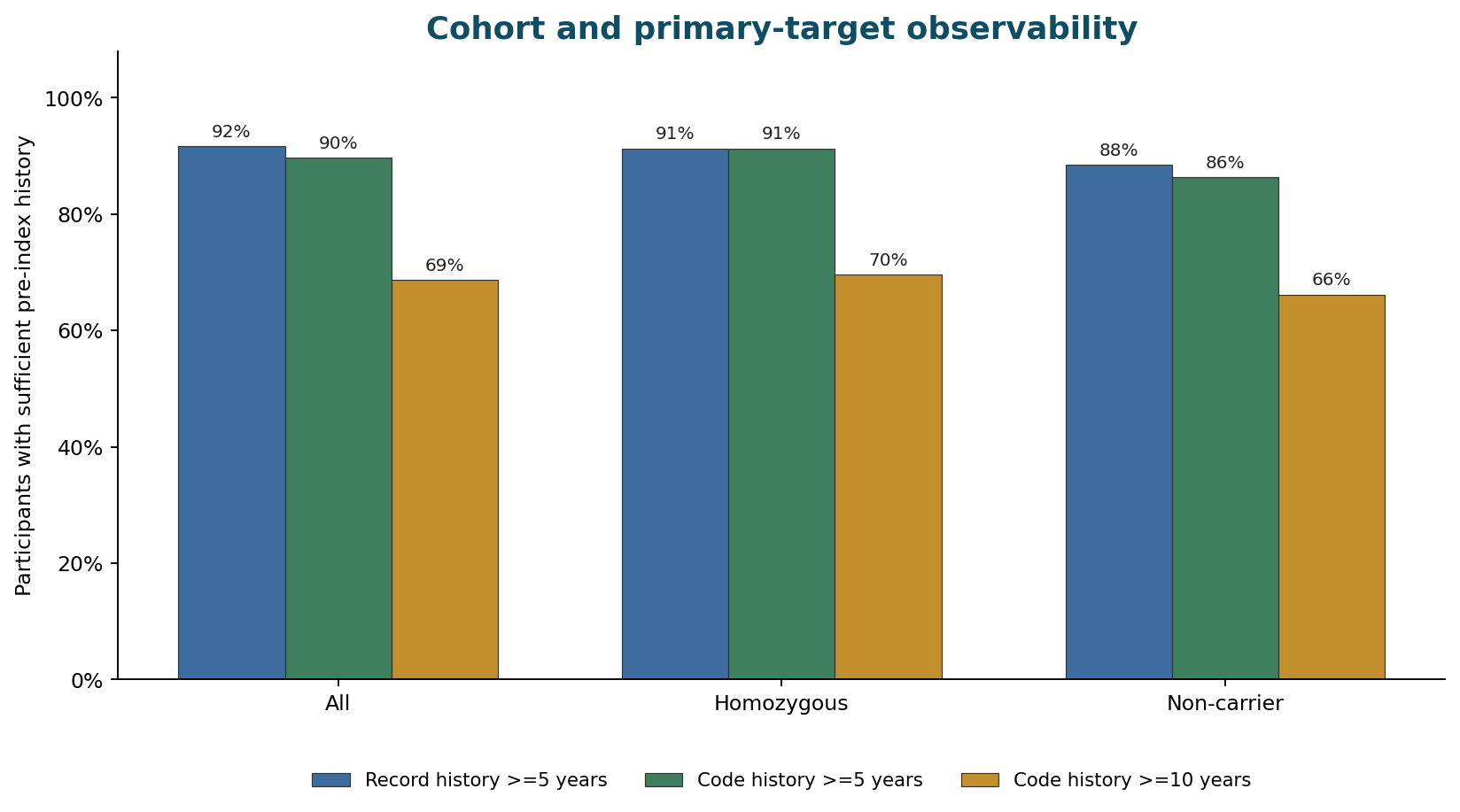
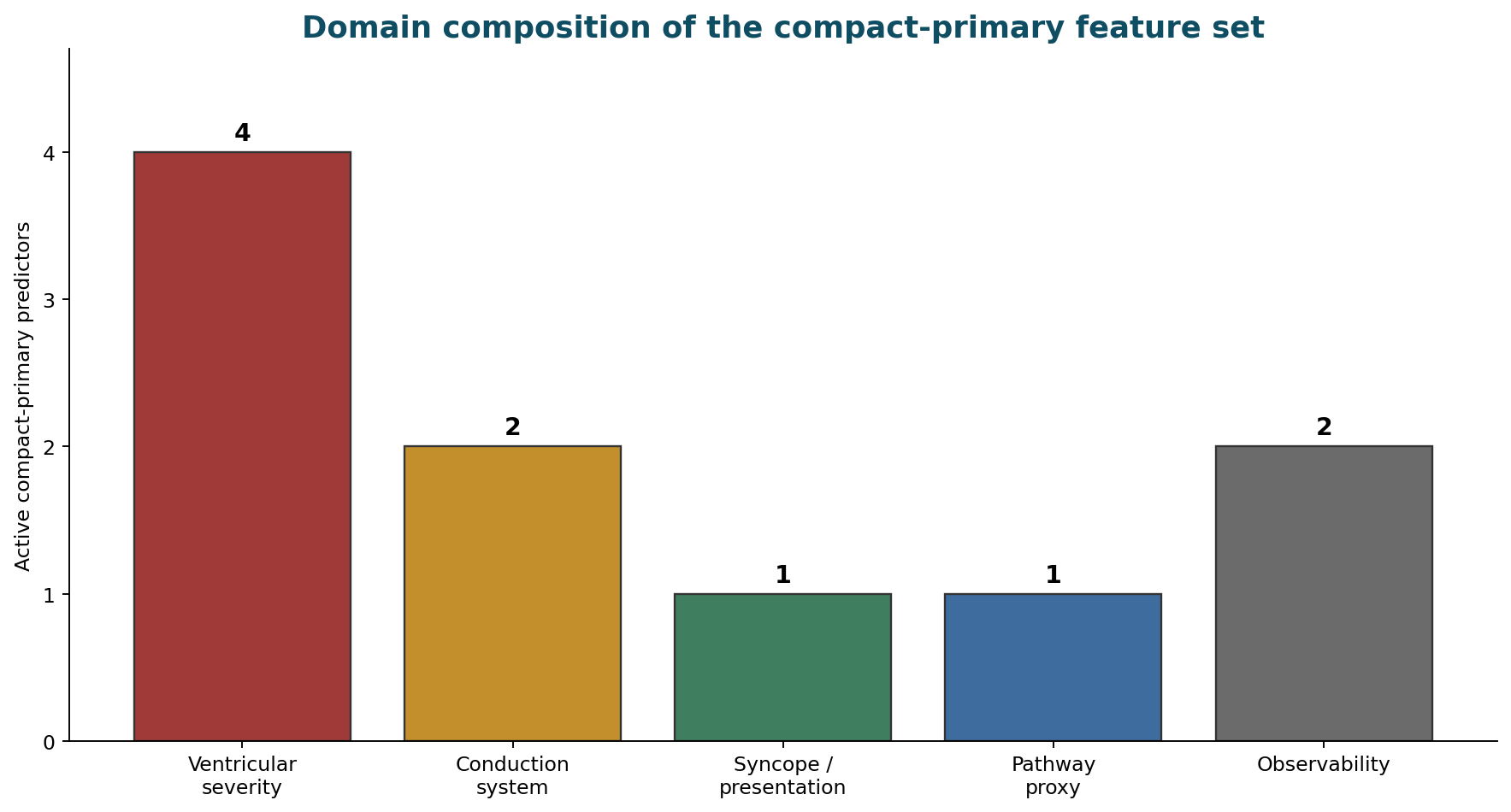
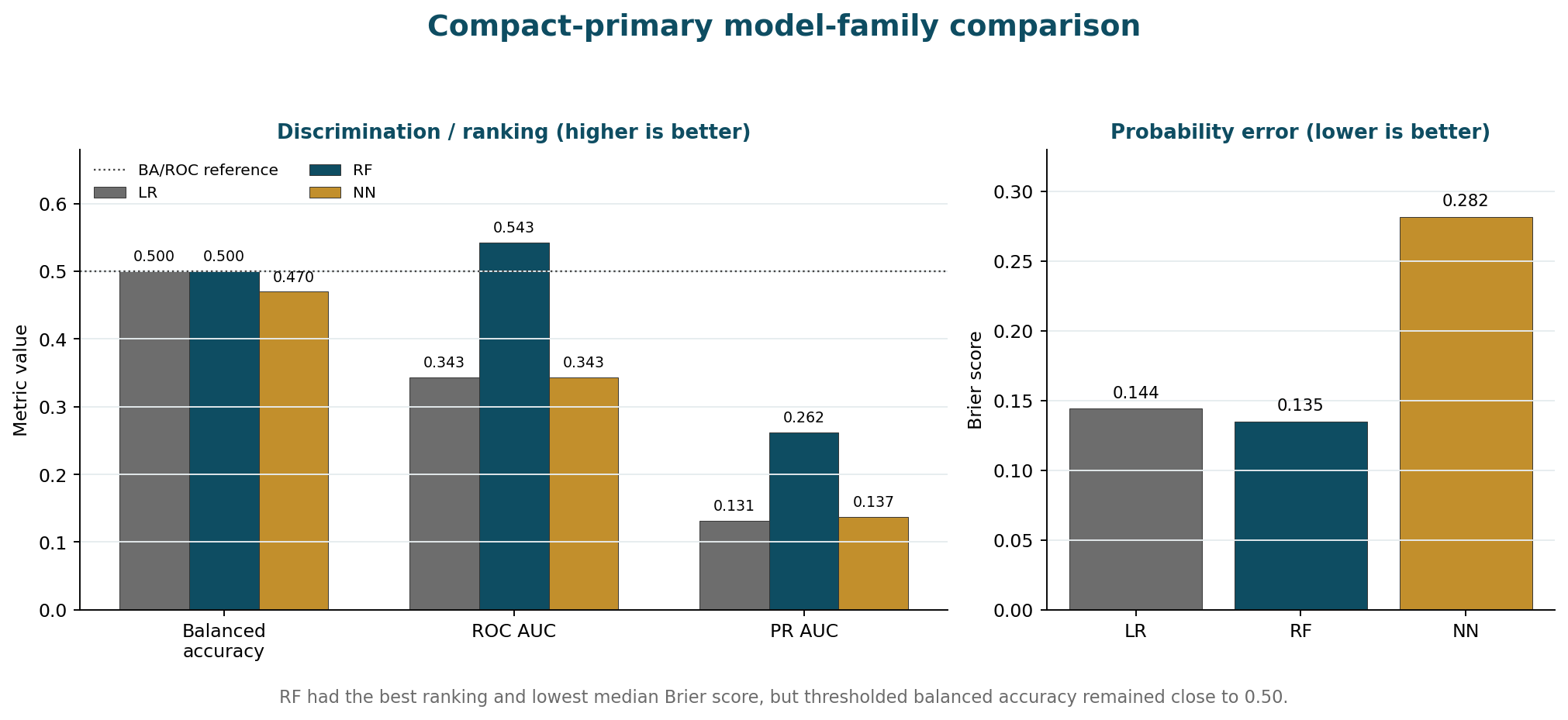
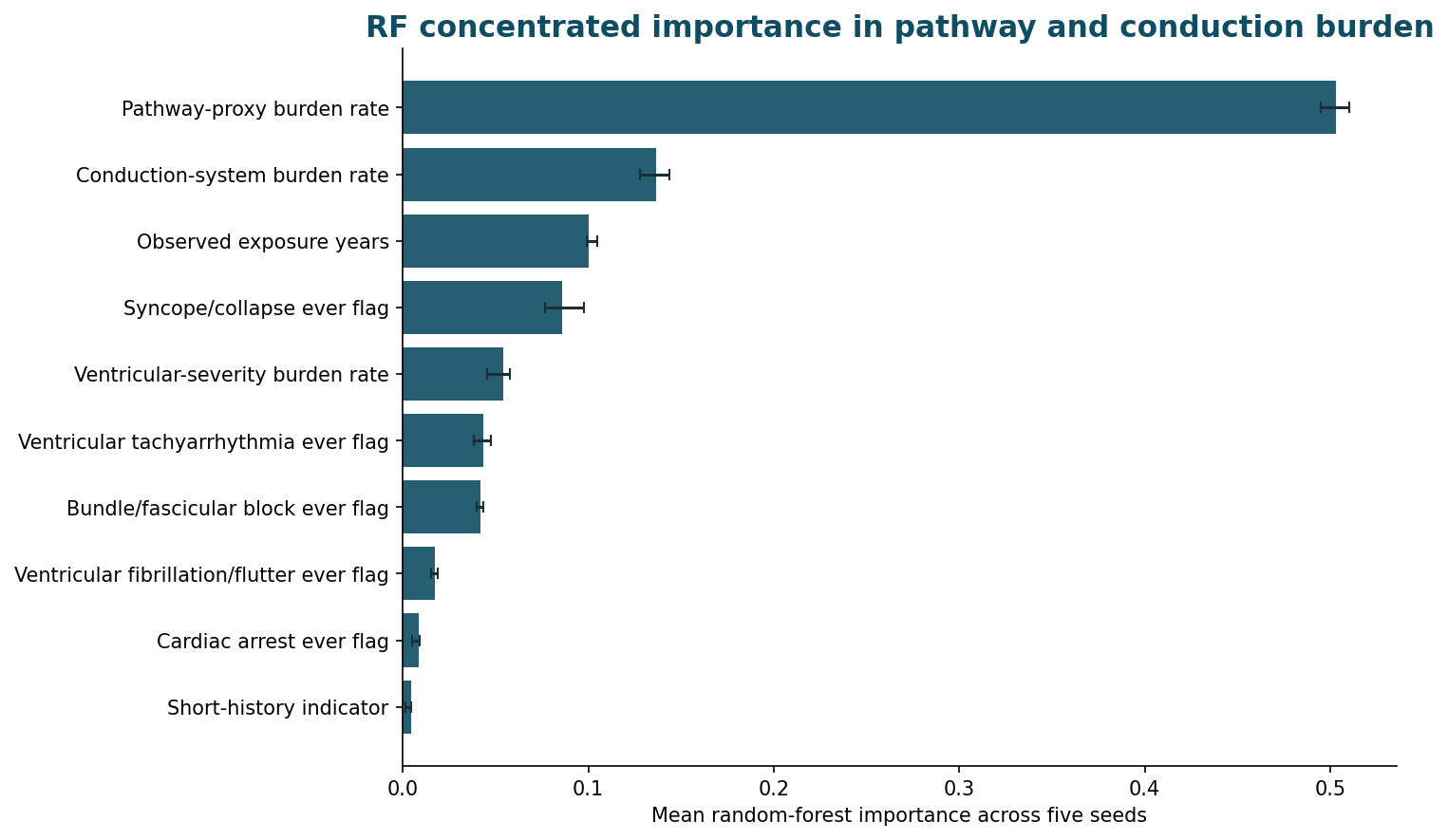
Cohort and event alignment
cohort["sequencing_date"] = pd.to_datetime(cohort["sequencing_date"], errors="coerce")
cohort["sequencing_date_missing"] = cohort["sequencing_date"].isna().astype(int)
cohort_index = cohort[["participant_id", "sequencing_date"]].drop_duplicates("participant_id")
apc_norm = prepare_hes_events(apc, "admidate", cohort_index, "hes_apc")
op_norm = prepare_hes_events(op, "apptdate", cohort_index, "hes_op")
ae_norm = prepare_hes_events(ae, "arrivaldate", cohort_index, "hes_ae")
apc_w_core = filter_window(apc_norm, core_window_years)
apc_w_recent = filter_window(apc_norm, recent_window_years)The feature build starts by normalising the cohort index and aligning hospital-event tables to pre-index windows.